zookeeper使用教程
zookeeper概念:
zookeeper是一个开源的分布式,为分布式应用提供协调工作的apache项目。
zookeeper机制:

zookeeper特点:
1.zookeeper:一个领导者(Leader),多个跟随着(Follower)组成的集群
2.集群中只要有半数以上节点存活,zookeeper集群都能正常服务,如果集群是4台,2台存活,集群不可服务,集群适合奇数台
3.全局数据一致,每个server保存一份相同的数据副本(因为存储文件小,所以不会造成内存压力),client无论连接到哪个server,数据都是一致的
4.更新请求顺序执行,来自同一个client的更新请求,按其发送顺序依次执行
5.数据更新原子性,一次数据更新,要么全部成功,要么全部失败
6.实时性,在一定时间范围内,client能读到最新数据
zookeeper数据结构:
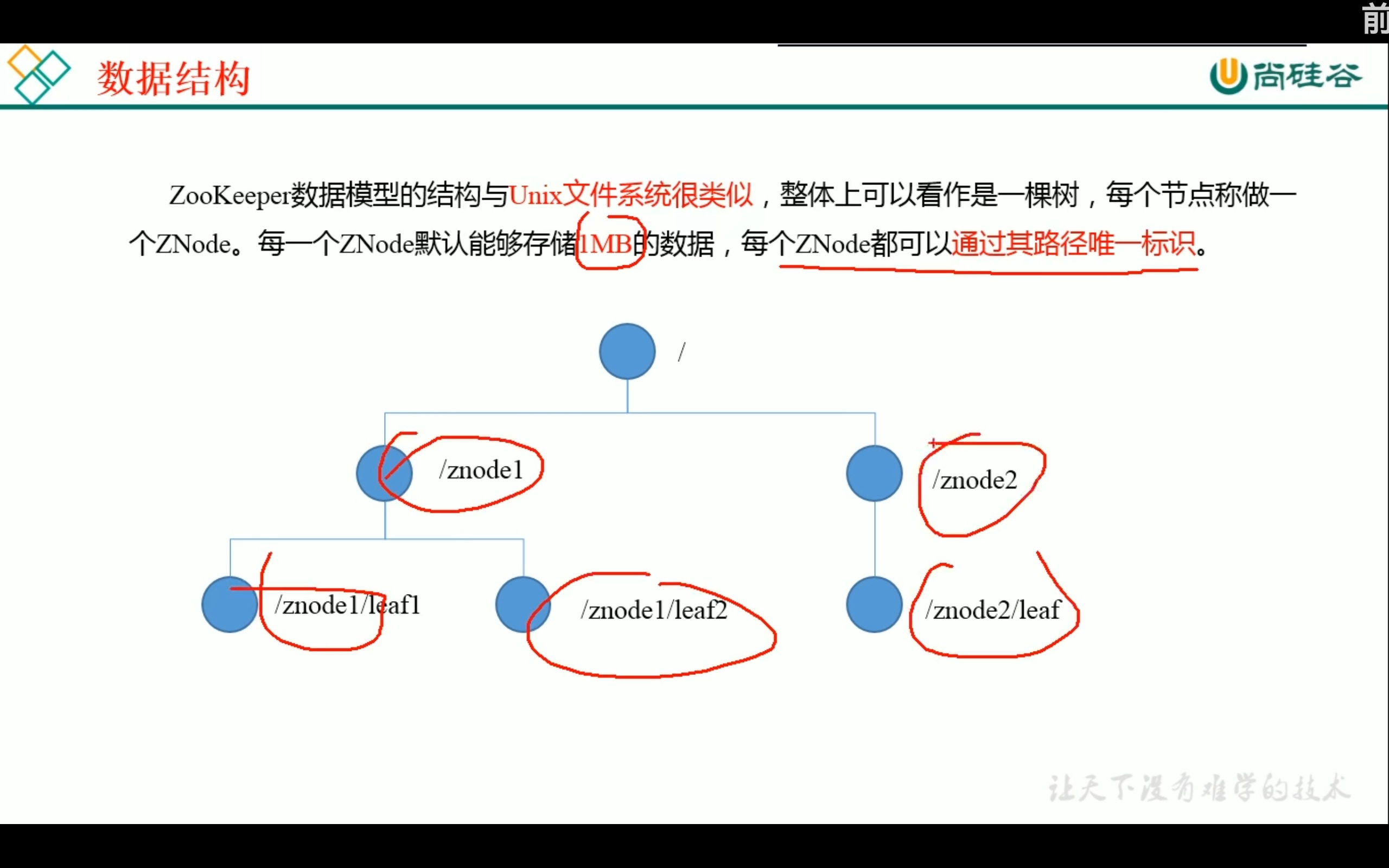
zookeeper应用场景:
1.统一命名服务
2.统一配置管理
3.统一集群管理,监控各个服务器的状态变化
4.服务器动态上下线,客户端能实时观察到服务器的上下线的变化
5.软负载均衡
zookeeper的安装:
1.下载,下载地址:https://downloads.apache.org/zookeeper/
2.安装
a.安装jdk
b.拷贝zookeeper包装包到linux系统/usr/local的目录下
c.解压:tar -zxvf zookeeper-3.4.10.tar.gz
3.修改配置
a.将/user/local/zookeeper-3.4.10/conf目录下的zoo_sample.cfg重命名为zoo.cfg:mv zoo_sample.cfg zoo.cfg
b.修改zoo.cfg文件,修改dataDir路径为 /user/local/zookeeper-3.4.10/zkData zkData目录要提前建好
zookeeper的操作
1.启动zookeeper:bin/zkServer.sh start
2.查看启动状态:bin/zkServer.sh status
3.启动客户端:bin/zkCli.sh
4.退出客户端:quit
5.停止zookeeper:bin/zkServer.sh stop
zookeeper配置参数解读:
zookeeper中的配置文件zoo.cfg中的参数含义解读如下:
1.rickTime=2000
通信心跳时间间隔2000毫秒,服务器之间或客户端与服务器之间维持心跳
备注:设置最小的session超时时间为两倍心跳时间,没理解
2.initLimt=10
集群中的Follower服务器与Leader服务器之间初始连接时,最多等待10个心跳数,10个心跳都检测失败,则Follower连接失败
3.syncLimit=5
在初始连接成功后,集群中的Follower服务器与Leader服务器之间超过5个心跳检测失败,Follower将被服务器列表中删除
4.dataDir
数据文件目录+数据持久化路径
5.clientPort=2181
客户端连接端口
zookeeper选举机制:
假设有1,2,3,4,5台服务器,1先给自己投一票,没有到3,没用。轮到2,2先给自己投一票,1也投给2一票,没到3,没用。轮到3,3先给自己一票,1和2也给3各投一票,达到了3票,3则设为了Leader服务器。轮到4,已设置Leader,跳过。轮到5,已设置Leader,跳过。集群只有一台Leader,其他都是Follower。
zookeeper节点类型:
持久:客户端和服务器断开连接后,创建的节点不删除
短暂:客户端和服务器断开连接后,创建的节点删除
共同特性:创建znode时设置顺序标志,znode名称后会附加一个顺序号的值。顺序号是一个递增的计数器,由父节点维护。在分布式系统中,客户端可以通过顺序号推断事件的顺序
学习zookeeper应用笔记:https://b23.tv/iSGVHJ